
Hashes are fancy math calculations that are used in many areas of computing. This post won’t be a discussion the math involved, but rather how the logic works. In the spirit of keeping things simple, let me try to answer what a hash is in the shortest terms possible:
A cryptographic hash function is a mathematic calculation performed on any input data (the message) that produces a fixed-size output (the hash or digest). Given only the digest, it’s virtually impossible to calculate the original message.
From here on out, for clarity, I’ll refer to the input as the message, and the output as the digest. Let’s get into a bit more detail and how it’s used.
Basic Concept
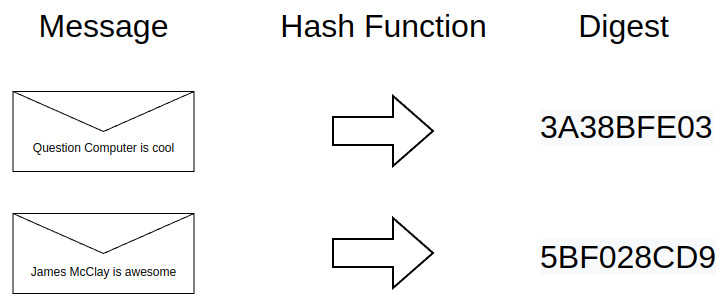
Digests are usually longer than the above example, and the message is usually not me patting myself on the back. But it serves to illustrate how a hash works. From this diagram, hopefully two additional points are clear:
- A message can be any kind of digital input, such as a file, a certificate, a string of characters, an image, an email, anything.
- The digest is binary, always the same length, and it’s usually represented in hexadecimal.
Simple use-case
A hash calculation is said to be “one-way”. This means that if someone had only the digest, computing the original message is virtually impossible.
Hash calculations provide this feature through the use of cryptographic algorithms (more on algorithms in a bit). “One-wayness” is useful in many different situations, but one such use-case might be to verify the integrity of something after it’s transmitted over a network.

As is tradition, let’s talk about Alice and Bob. If Alice sent Bob an email, and Bob wanted to know that the email was not changed in during transit, hashes can be used to verify the email’s integrity. If Alice runs a hash using the email as input and sends the digest to Bob, Bob can run the same hash on the email he received from her and check to see if the digest Alice provided is the same as the digest he calculated on the email he received. If they’re the same, the message integrity is intact.
This leaves several questions open, such as:
- Through what means does Bob receive Alice’s digest?
- How does he know the received digest is intact?
- Couldn’t an attacker change the email and the hash, without Alice or Bob knowing?
Those are valid questions, and out of the scope of this article and not part of hashing functions themselves. If you want to know, I’d encourage you to read about Public Key Infrastructure as a whole and how hashes fit in.
Algorithms
An algorithm is basically the steps involved in the hash calculation. Here are a few of the most common:
- MD5 – Message Digest algorithm. An older algorithm and generally considered insecure, but still widely used.
- SHA – Secure Hash Algorithm. Includes a family of algorithms, including SHA-1 (considered insecure) SHA-2, and the newest algorithm SHA-3.
- CRC32 – Cyclic Redundancy Check. Often used to detect errors in network packets.
These algorithms are used in everything from checking file integrity to securing network connections from attack. Keep in mind, the are usually used in combination with other calculations and algorithms to completely secure data. Hashes are just one piece of the larger puzzle.
Examples – python and bash
Below is a basic example of how to perform a SHA-1 hash in python. We’re simply going to borrow the power of the hashlib module and perform our own hash:
import hashlib message = "Question Computer is cool" digest = hashlib.sha1(message.encode()).hexdigest() print(digest) '9da75cf04f541a737c89585b582e60a33f4967ed'
We take the string “Question Computer is cool” as a message, run it through the SHA-1 hash calculation, and get a hexadecimal digest of 9da75cf04f541a737c89585b582e60a33f4967ed.
Below we perform the same SHA-1 has, this time in Bash using the openssl command line interface . This command should work on most Linux distributions:
echo -n "Question Computer is cool" | openssl dgst -sha1 ---- SHA1(stdin)= 9da75cf04f541a737c89585b582e60a33f4967ed
You’ll notice that even though we’re not using Python or hashlib this time (we’re using the openssl CLI), the same string “Question Computer is cool” served as the input, and the exact same digest was generated.
Other features
Hashes have some other notable interesting features that are worth mentioning:
- Multiple hash calculations on the exact same message will produce exactly the same digest.
- Digests are of a fixed size. The output is always the same number of bits, no matter the size or format of the input.
- Digests are, for all intents and purposes, unique. Their algorithm determines the length of the digest, which in turn determines the number of available unique digests. For most algorithms, this is an astronomically huge number.
- Hash functions have a “collision domain”, which is the likelihood that two different messages produce the same digest. The likelihood is extremely low (depends on the algorithm), but not impossible.
Happy hashing!