
It’s time to check in, once again, on my old friend Free Range Routing (FRR). I’ve been a fan of this project ever since its inception at Cumulus Networks, which was acquired by Nvidia in 2020. FRR is a fork of the trusty old IP routing protocol suite, Quagga. FRR adds on many new features, protocols and general improvements to the suite, and it’s open source of course.
Today let’s look at how to install the most recent version of FRR (as of this writing), 8.4 on Ubuntu and get EIGRP up and running (Hint: it’s really easy now!).
Topology
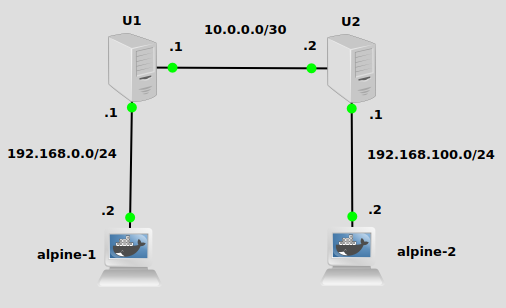
In order to illustrate the EIGRP protocol working, we have three subnets in place. I’ve already configured default routes on the alpine docker containers pointing to U1 and U2 (see this post on how to set up docker in GNS3). I’ve also enabled IP forwarding on U2 and U2, of course. Our challenge today is to make U1 aware of 192.168.100.100/24, and U2 aware of 192.168.0.0/24. That way when alpine-1 at 192.168.0.2/24 pings 192.168.100.2/24, U1 and U2 will know how to properly route traffic.
Installation
I found official installation instructions for Debian-based Linux distributions here on the FRR website. But just in case that link changes between now and the time you’re reading this, here are the steps I followed:
# add GPG key curl -s https://deb.frrouting.org/frr/keys.asc | sudo apt-key add - #add respository to apt sources FRRVER="frr-stable" echo deb https://deb.frrouting.org/frr $(lsb_release -s -c) $FRRVER | sudo tee -a /etc/apt/sources.list.d/frr.list # update and install FRR sudo apt update && sudo apt install frr frr-pythontools
That should do it as far as installation. Then we need to enable the EIGRP daemon, by editing the /etc/frr/daemons text file. We’re looking for a line that says eigrpd=no and we’ll change it to eigrpd=yes. You can use your favorite editor, or I found this sed command to work very nicely:
sudo sed -i s/eigrpd=no/eigrpd=yes/g /etc/frr/daemons
Now restart FRR:
systemctl restart frr
The EIGRP daemon should now be up and running!
Configuration
If you’re familiar with the original Quagga, it was designed with a Cisco-like interactive CLI separate from Bash. FRR has this configuration tool as well, it’s called vtysh. To enable EIGRP routing and start advertising routes, will run these commands on U1:
vtysh ---- Hello, this is FRRouting (version 8.4). Copyright 1996-2005 Kunihiro Ishiguro, et al. james# conf t james(config)# router eigrp 10 james(config-router)# network 10.0.0.0/30 james(config-router)# network 192.168.0.0/24 james(config-router)# james# james# wr Note: this version of vtysh never writes vtysh.conf Building Configuration... Integrated configuration saved to /etc/frr/frr.conf [OK] james#
And on U2, we’ll run similar commands except we’ll be advertising 192.168.100.0/24 instead.
vtysh ---- Hello, this is FRRouting (version 8.4). Copyright 1996-2005 Kunihiro Ishiguro, et al. james# conf t james(config)# router eigrp 10 james(config-router)# network 10.0.0.0/30 james(config-router)# network 192.168.100.0/24 james(config-router)# james# james# wr Note: this version of vtysh never writes vtysh.conf Building Configuration... Integrated configuration saved to /etc/frr/frr.conf [OK] james#
EIGRP should now be advertising routes!
Verification
Let’s first verify that EIGRP hello packets are actually going across the link between U1 and U2, 10.0.0.0/30. A wireshark capture in GNS3 will do the trick:
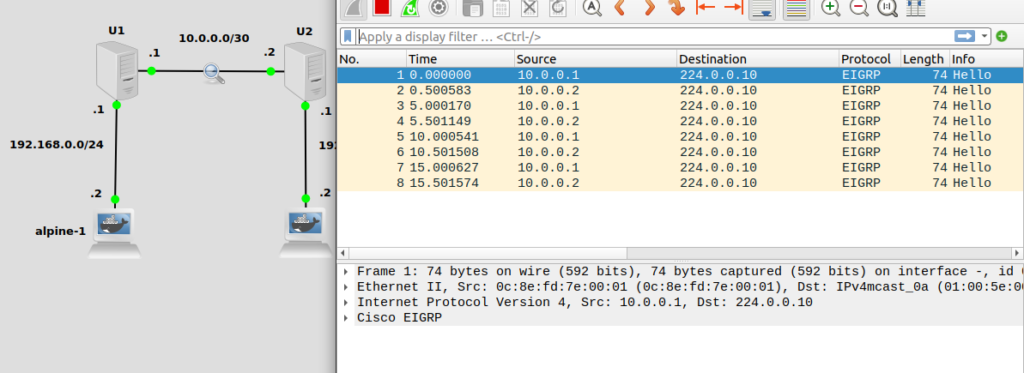
Looks like the hello’s are working ok. Let’s verify that U1 has received the 192.168.100.0/24 route. We can do this either from vtysh or just using the Linux iproute2 command, but for fun I’ll use vtysh:
james# show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, F - PBR,
f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
E 10.0.0.0/30 [90/28160] is directly connected, ens4, weight 1, 00:30:15
C>* 10.0.0.0/30 is directly connected, ens4, 00:30:15
E 192.168.0.0/24 [90/28160] is directly connected, ens3, weight 1, 00:30:35
C>* 192.168.0.0/24 is directly connected, ens3, 00:30:35
E>* 192.168.100.0/24 [90/30720] via 10.0.0.2, ens4, weight 1, 00:24:00
Looking good! Here’s U2, making sure we have the 192.168.0.0/24 route:
james# show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, F - PBR,
f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
E 10.0.0.0/30 [90/28160] is directly connected, ens4, weight 1, 00:25:46
C>* 10.0.0.0/30 is directly connected, ens4, 00:25:46
E>* 192.168.0.0/24 [90/30720] via 10.0.0.1, ens4, weight 1, 00:25:42
E 192.168.100.0/24 [90/28160] is directly connected, ens3, weight 1, 00:25:46
C>* 192.168.100.0/24 is directly connected, ens3, 00:25:46
And finally, let’s ping from alpine-1 at 192.168.0.2 to alpine-2 at 192.168.100.2:
/ # hostname alpine-1 / # ip route default via 192.168.0.1 dev eth0 192.168.0.0/24 dev eth0 scope link src 192.168.0.2 / # ping 192.168.100.2 -c 1 PING 192.168.100.2 (192.168.100.2): 56 data bytes 64 bytes from 192.168.100.2: seq=0 ttl=62 time=2.715 ms
EIGRP on Ubuntu 22.04! Take that, Cisco!